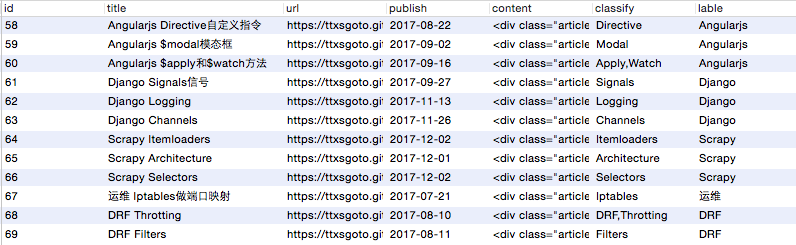
"""
- scrapy + selenium 爬取ttxsgoto.github.io 文章
- 主要用来练习scrapy和selenium结合完成抓取工作
- 使用过程非标准scrapy框架
"""
import datetime
import logging
from urllib import parse
import scrapy
import time
from scrapy.http import HtmlResponse
from selenium import webdriver
from scrapy.xlib.pydispatch import dispatcher
from scrapy import signals
from tutorial_spider.items import TtxsgotoItem
from tutorial_spider.pipelines import TtxsgotoBlogMysqlchemyPipeline
logger = logging.getLogger(__name__)
class TtxsgotoSpider(scrapy.Spider):
name = 'ttxsgoto'
allowed_domains = ['ttxsgoto.github.io']
start_urls = ['http://ttxsgoto.github.io/']
def __init__(self, *args, **kwargs):
self.driver = webdriver.Chrome()
self.driver.maximize_window()
logger.info("开始爬取ttxsgoto.github.io数据")
super(TtxsgotoSpider, self).__init__(*args, **kwargs)
dispatcher.connect(self.close_driver, signals.spider_closed)
def close_driver(self, spider):
'''
关闭浏览器
'''
self.driver.quit()
def start_requests(self):
self.driver.get(self.start_urls[0])
res = HtmlResponse(url='index html', body=self.driver.page_source, encoding="utf-8")
title_text = res.css('#main section h1 a::text')[0].root.strip()
self.driver.find_element_by_link_text(title_text).click()
time.sleep(2)
if title_text in self.driver.page_source:
self.detail_parse(self.driver.page_source, title_text)
while True:
try:
key_word = self.driver.find_elements_by_class_name("next")[0].text
except (TypeError,IndexError):
self.driver.quit()
key_word = None
if not key_word:
break
self.driver.find_element_by_link_text(key_word).click()
time.sleep(2)
res = HtmlResponse(url='next html', body=self.driver.page_source, encoding="utf-8")
title_text = res.css('.article-info h1 a::text').extract_first()
self.detail_parse(self.driver.page_source, title_text)
def detail_parse(self, page_source, title):
res = HtmlResponse(url='detail html', body=page_source, encoding="utf-8")
item = TtxsgotoItem()
item['title'] = title
_url = res.css('#main h1 a::attr(href)').extract_first()
item['url'] = parse.urljoin(self.start_urls[0], _url)
item['publish'] = res.css('.article-time time::text').extract_first()
item['content'] = res.css('.article-content').extract_first()
classify_list = res.css('.article-tags a::text').extract()
item['classify'] = ','.join(classify_list)
item['lable'] = res.css('.article-categories a::text').extract_first()
item['create_time'] = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
pipeline = TtxsgotoBlogMysqlchemyPipeline()
pipeline.process_item(item, self.name)