Scrapy Architecture
架构
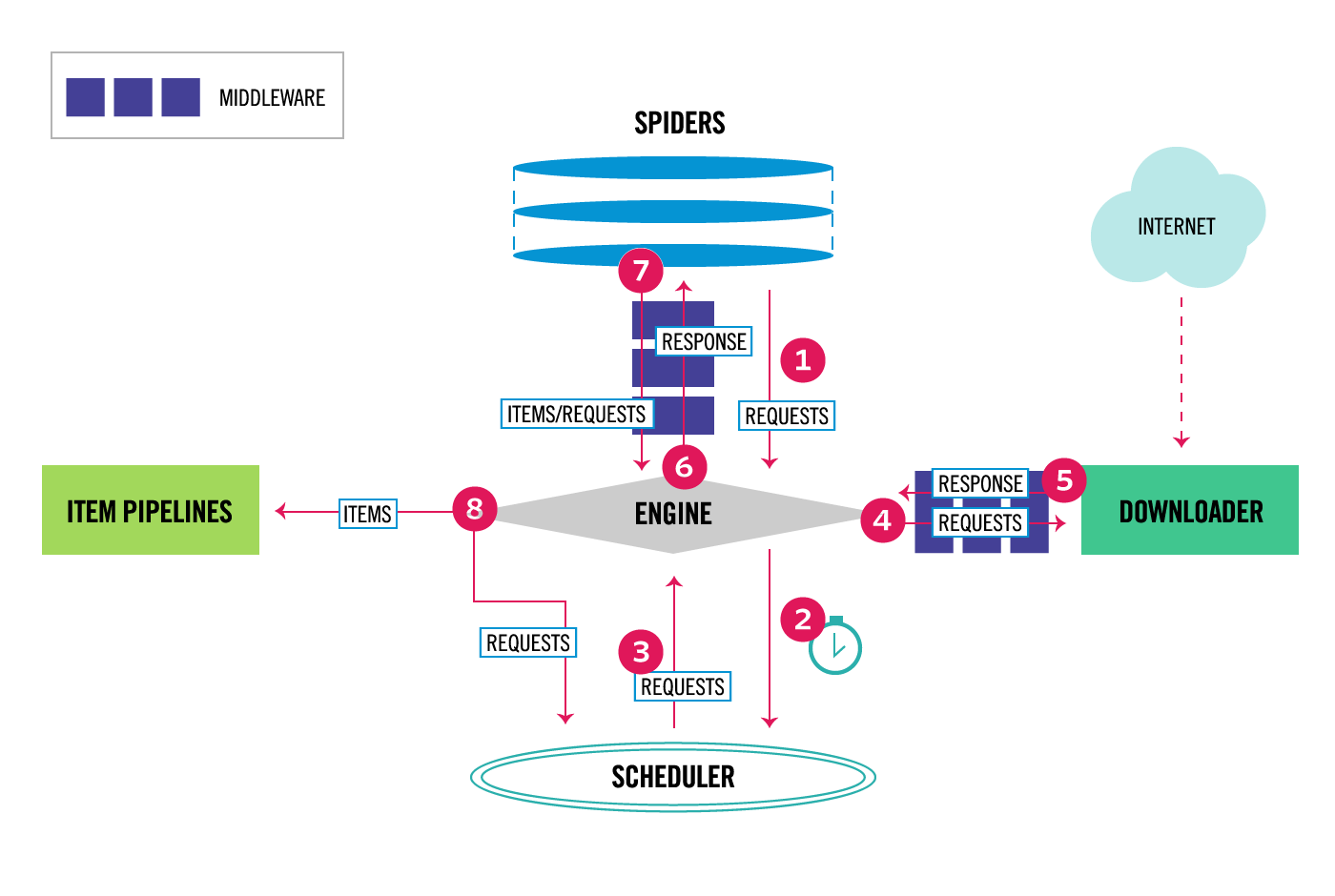
所有过程的流向都依赖于 ENGINE 模块
1.Engine从Spider中得到初始的Requests,Requests将被用来进行爬取;
2.Engine将得到的Requests放入Scheduler中,然后不断从Scheduler询问下次可以进行爬去的Requests;
3.Scheduler返回下一次需要被爬取的Requests给Engine;
4.Engine将Requests发送给Downloader,通过Downloader Middlewares 的process_request() 方法进行传递;
5.Downloader完成了对该页面的下载,Downloader将会生成一个与该页面相关的Response对象,通过Downloader Middlewares的process_response()方法进行传递,将其反馈给Engine;
6.Engine从Downloader得到Response再发送给Spider进行处理;通过Spidder Middlewares的process_spider_input()方法进行传递;
7.Spider 处理从Engine返回的Reponse对象,返回被爬取的items和新的Requests给Engine继续处理,通过Spider Middlewares的process_spider_output()方法进行传递;
8.Engine发送已经被处理的Items到Item Pipelines,然后将新的Requests发送给Scheduler请求下一次可能的新的Request进行爬取;
9.再重复整个流程,直到Scheduler中没有新的Requests
Scrapy主要模块
- Engine:核心引擎来控制所有组件之间的数据流向
- Scheduler:从Engine当中获取Requests,然后将它们放入队列当中,当Engine需要再触发
- Downloader:主要是取得web页面,然后将它们返回给Engine,Engine再反馈给Spider
- Downloader middleware:位于Engine和Downloader之间的一个特殊的“钩子(hook)”,主要处理从Engine发送给 Downloader的Requests,以及从Downloader传递给Engine的Responses
- Spiders:自定义类,用来解析Responses并提取相关的元素items
- Spider middleware:是Engine和Spiders之间的一个特殊的钩子(hook),主要处理spider的input(reponses)和output(items和requests)
- Item Pipeline:处理Spider提取完成的items,对数据进行清洗,验证和持久化处理